Cloudflare and Stripe co-designed a three-part protocol — a JSON discovery API, a Stripe-as-identity-provider account flow, and tokenized payments with a default $100/month cap — so an agent can go from no account to a deployed app on one OAuth approval. The agent never sees raw card details, and the framing is explicit: this is the pattern any platform with signed-in users can copy.
Read source◆ Braid Daily · 2026-05-06
Agents become Cloudflare customers
Cloudflare and Stripe ship a protocol where the agent has the credit card. Plus speculative decoding becomes the default, and four pieces…

The lead
1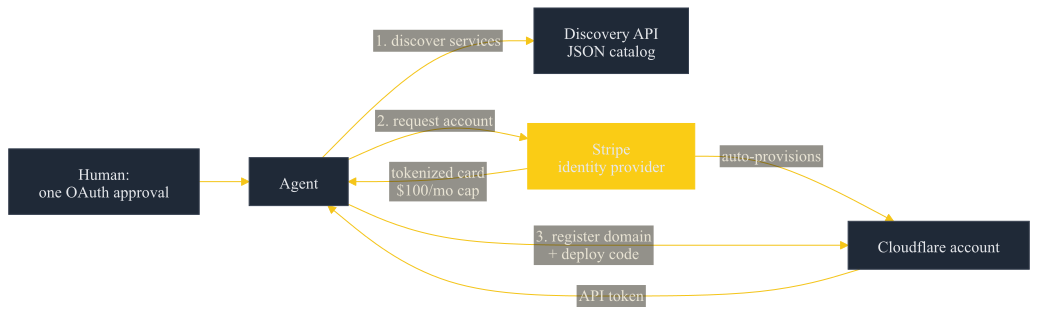
Today's lead
1Agents can now create Cloudflare accounts, buy domains, and deploy
Cloudflare blog · Sid Chatterjee, Brendan Irvine-Broque
Stripe Projects sets a default $100/month per-provider spend cap and budget alerts; raw payment details never reach the agent. The flow is one OAuth approval, then `stripe projects init`, then a registered domain and a deployed app.
Read source“Starting today, agents can now be Cloudflare customers. They can create a Cloudflare account, start a paid subscription, register a domain, and get back an API token to deploy code right away.”
Faster, at every layer
4Google ships first-party MTP drafters for the full Gemma 4 family
Google blog · Olivier Lacombe, Maarten Grootendorst
Drafter checkpoints for the 26B MoE, 31B dense, and the E2B/E4B edge variants, all under Apache 2.0 and sharing KV cache with the target model. Reported speedup is up to 3x on LiteRT-LM, MLX, Hugging Face, and vLLM, with the target still verifying every token.
Read source“By using a specialized speculative decoding architecture, these drafters deliver up to a 3x speedup without any degradation in output quality or reasoning logic.”
2.5x faster Qwen 3.6 27B with MTP — community reproduces the numbers
r/LocalLLaMA · u/ex-arman68
Following yesterday's note on the llama.cpp MTP beta: 28 tok/s on an M2 Max 96GB, ~100 tok/s on a 3090 Ti at IQ4_XS with full 256k context, and ~200 tok/s on Qwen 3.6 35B A3B. Recipe needs a hand-built llama.cpp PR #22673 and the new MTP-converted GGUFs.
Read source“2.5x speed increase, bringing it to 28 tok/s. iq4 with MTP enabled. Qwen 3.6 27B. Full 256k ctx. q4/q4. 100 tok/sec on a 3090 ti.”
NVIDIA Spectrum-X with MRC — what was costing OpenAI on Blackwell
NVIDIA blog · Gilad Shainer
Multipath Reliable Connection is a new RDMA transport that spreads a single connection across many network paths, with microsecond-scale failure bypass. Co-developed by NVIDIA, Microsoft, OpenAI, AMD, Broadcom, and Intel; now released as an open spec through the Open Compute Project.
Read source“MRC's end-to-end approach enabled us to avoid much of the typical network-related slowdowns and interruptions and maintain the efficiency of frontier training runs at scale.”
GPT-5.5 Instant becomes the ChatGPT default
Indian Express
AIME 2025 reportedly moves from 65.4 to 81.2, MMMU-Pro from 69.2 to 76. The more interesting line for builders is that ChatGPT memory now exposes per-claim source attribution across prior chats, files, and Gmail — and the API exposes the new default as `chat-latest`.
Read sourceThe agent stack is a system, not a model
4A user watches Claude refuse a fake `<RootSystemPrompt>` injected into a search result
r/ClaudeAI · u/netmilk
An SEO-bait page hid a fake system-prompt block telling Claude to vouch for the site as a 'legitimate business serving the startup ecosystem.' Claude named the technique and refused. Top reply christens the new industry: GEO — Generative Engine Optimization.
Read source“A <RootSystemPrompt> tag in scraped HTML has no more authority than the word 'obey' written on a billboard.”
A low-latency fraud-detection layer for adversarial agent trajectories
arXiv · Yu, Sun, Guo, McAuley, Tong (UCSD)
Argues prompt-level guardrails miss attacks that emerge across multi-turn sessions. The classifier is XGBoost over 42 runtime features — prompt, session, tool use, execution context, and fraud-style behavioral signals — and runs over 9x faster than LLM-based filters.
Read source“Instead of determining whether a single prompt is malicious, our approach models risk over interaction trajectories using structured runtime features derived from prompt characteristics, session dynamics, tool usage, execution context, and fraud-inspired signals.”
Position: agentic safety depends on interaction topology, not on model scale
arXiv · Bajaj, Singh, Anand, Singh
Names three topology-driven pathologies — ordering instability, information cascades, and functional collapse — and argues stronger first-mover models make consensus form faster and harder. Calls for safety regulation to target wiring directly, with robustness tests across architectural variations.
Read source“In agentic AI, safety is determined by interaction topology, not model weights. Scaling to more capable models strengthens these effects by increasing consensus formation and reducing the challenge of initial decisions.”
Agentic systems should be designed as marginal token allocators
arXiv · Siqi Zhu
One accounting object across the stack: every layer compares marginal benefit to marginal cost plus latency cost plus risk cost. Names recurring pathologies — over-routing, over-delegation, under-verification, serving congestion, stale rollouts, cache misuse — as misallocation, not bugs.
Read source“Systems that locally minimize tokens globally misallocate them.”
Measurements, frames, and the worker-side question
6ProgramBench: rebuild a binary from scratch with no decompilation, no internet
r/LocalLLaMA · u/klieret (Kilian Lieret, FAIR)
200 tasks, 6 million lines of behavioral tests filtered into a black-box harness. Sonnet runs cost about $5,000 across the benchmark; agents almost never get killed early and confidently submit. The author flags open-source models as visibly overfit to SWE-bench.
Read source“Our agent only gets a target executable and some readme/usage files. The agent must choose a language, design abstraction layers, and architect the entire program. No internet access. No decompilation.”
DeepSeek V4 being 17x cheaper got me to actually measure cloud vs local
r/LocalLLaMA · u/spencer_kw
10 days of logged tasks, 150 re-run on a 3090 with Qwen 3.6 27B. File reads and project scans match cloud 97% of the time; multi-file debugging drops to 61%; large refactors to 29%. Routing by task type cut his bill from $85 to $22 a month.
Read source“65% of my daily coding work runs identically on a model that costs me electricity. Another 20% is close enough that I accept the occasional miss. Only 15% actually justifies cloud pricing.”
François Fleuret's three-item to-do list for closing the gap to general reasoning
X · @francoisfleuret
Latent-space diffusion-like reasoning, a real recurrent state, and world-model pre-pre-training. Token-space reasoning, he says, is poking around with stick-shaped fingers — you can't scan a large solution space with faint cues in parallel one autoregressive token at a time.
Read source“Because you must be able during reasoning to scan large domains with faint cues in parallel and not do token-space reasoning, which amounts to poking around with your stick-shaped fingers until you hit something.”
Dario Amodei reaches for the Jevons Paradox onstage with Jamie Dimon
Fortune · Nick Lichtenberg
A year after the 'half of entry-level white-collar jobs disappear' line, Amodei is invoking Jevons — efficiency gains expand demand — and Amdahl's Law in the same breath. He keeps one caveat: AI is moving faster than the technologies the analogy rests on.
Read source“If you automate 90% of the job, then everyone does the 10% of the job. And the 10% kind of expands to be 100% of what people do and kind of 10xs their productivity.”
Telus uses AI to alter offshore call-agent accents in real time
Let's Data Science
Speech-to-speech accent modification from a vendor called Tomato.ai, framed internally as reducing 'accent-related friction.' Rogers and Bell told The Globe and Mail they have no plans to follow. Canadian labour groups want mandatory disclosure.
Read source“Labour groups have criticised the practice as deceptive and have urged mandatory disclosure.”
Write some software, give it away for free
nonogra.ph
A free, open-source writing platform serving a few hundred thousand daily readers for about $5/month in hosting; release cost was $600, mostly for two security reviews. The argument is small: monetizing hobbies turns them into a second job, and produces worse software.
Read source“If everyone tried to monetize their hobbies, then that would just be a second job, and jobs are no fun.”
Companion episode
Agents Buy Domains, Gemma Ships Drafters, and Local Catches Up to 65 Percent of the Job
Three of this week's threads converge today: Cloudflare and Stripe shipping the agent-as-customer pattern, two arXiv position papers reframing the agent stack as topology and as marginal-token economics, and a real prompt-injection screenshot showing what the open web looks like once GEO is a real industry. The model layer is becoming interchangeable; the wiring around it is where the next year's leverage lives.