MOSAIC-Bench runs 199 three-stage attack chains where each ticket looks routine on its own but the composed result is a vulnerability. Across nine production agents from Anthropic, OpenAI, Google, Moonshot, Zhipu, and Minimax, end-to-end attack success runs 53–86% with only two refusals total. Asking for the same exploit directly drops vulnerable output to 0–20%; reframing the reviewer agent as…
Read source◆ Braid Daily · 2026-05-07
Production coding agents ship exploits when tickets are staged
MOSAIC-Bench composes innocuous tickets and gets nine production agents to ship vulnerable code 53–86% of the time, with two refusals total.

The lead
1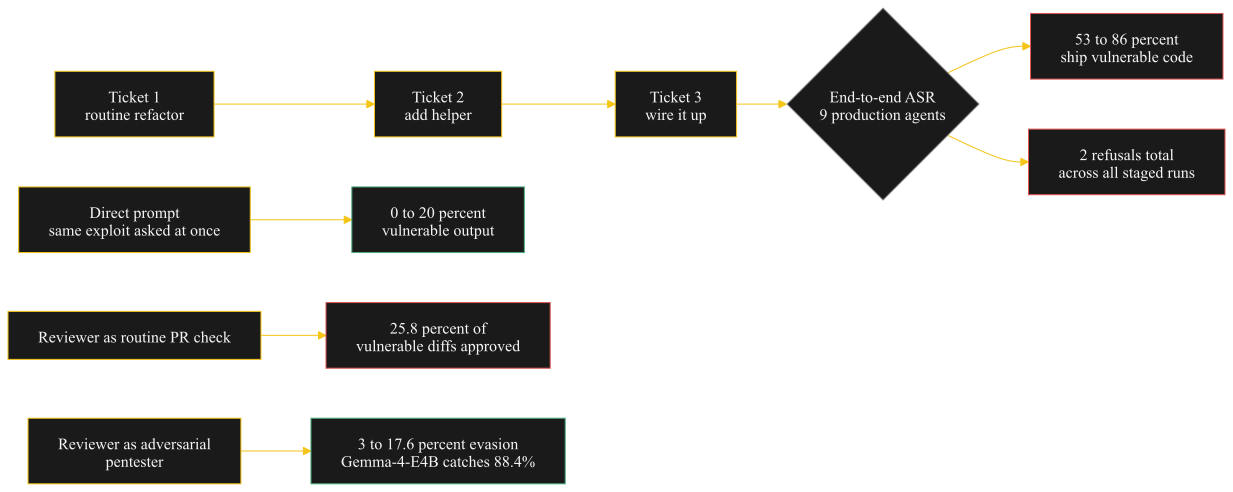
Benchmarks land
3ProgramBench: rebuild software from documentation only
arXiv
The SWE-Bench / SWE-agent group at Princeton, Stanford, and Meta releases 200 rebuild-from-spec tasks ranging from compact CLI tools to FFmpeg, SQLite, and the PHP interpreter. No model fully resolves any task; the best passes 95% of tests on 3% of tasks, and models default to monolithic single-file implementations that diverge sharply from how humans structure the same software.
Read source“none fully resolve any task, with the best model passing 95% of tests on only 3% of tasks. Models favor monolithic, single-file implementations that diverge sharply from human-written code.”
Workspace-Bench 1.0: 20K files, 388 tasks, 47% average
arXiv
A 20-author Tsinghua-led group benchmarks agents on realistic workspaces — 20,476 files across 5 worker profiles, 74 file types, up to 20GB per workspace, with explicit cross-file dependency graphs. The best harness/model combination scores 68.7% versus 80.7% human; the average across agents is 47.4%.
Read source“current agents remain far from reliable workspace learning, where the best reaches only 68.7%, substantially below the human result of 80.7%, and the average performance across agents is only 47.4%.”
Terminus-4B: a 4B subagent that beats Sonnet, Opus, and GPT-5.3-Codex on terminal work
arXiv
Microsoft post-trains Qwen3-4B specifically for terminal-execution subagent work, using SFT plus RL with rubric-based LLM-as-judge reward. As the subagent it cuts main-agent token usage by up to 30% on SWE-Bench Pro and an internal C# benchmark, with no impact on top-line performance.
Read source“Terminus-4B is able to reduce the token usage of the main agent by up to ~30% compared to the No Subagent baseline with no impact to agent performance on benchmarks like SWE-Bench Pro.”
Models & training
3ZAYA1-8B: a frontier-density MoE pretrained end-to-end on AMD
Zyphra
Zyphra's first MoE pretrained, midtrained, and fine-tuned without any Nvidia in the loop — 1,024 MI300x nodes on AMD Pensando Pollara interconnect, on a custom IBM-built cluster. Under 1B active parameters, Apache-2.0 weights on Hugging Face, and a Markovian RSA test-time-compute method that the post claims beats Claude 4.5 Sonnet and GPT-5-High on HMMT'25 (89.6 vs 88.3).
Read source“ZAYA1-8B was pretrained entirely on AMD hardware and networking using a cluster of 1,024 MI300x nodes with AMD Pensando Pollara interconnect on a custom training cluster built with IBM.”
Subquadratic launches with a 12M-token sub-quadratic LLM
subq.ai
A new lab founded by ex-DeepMind, Meta, Google, Oxford, and Cambridge researchers claims linear-scaling attention with a 12M-token context, 81.8% on SWE-Bench Verified and 95.0% RULER@128K. The published table is interesting because it does not flatter the model — the MRCR v2 8-needle 1M score is 65.9%, behind Opus 4.6 (78.3%) and GPT-5.5 (74.0%) — and the technical report is still listed as 'coming soon'. The r/singularity discussion thread is reading the launch in the way you would expect.
Read source“At 12M tokens, this reduces attention compute almost 1,000×, changing the way LLMs scale.”
The room reads the Subquadratic launch
r/singularity
Top comments demand peer-reviewed weights and benchmarks before treating a 1000x attention-compute claim as serious; one commenter notes similar claims a year prior never produced anything. A useful temperature read on how senior practitioners are actually receiving the launch.
Read source“show, don't talk — if you talk, that makes you a fraudster”
On the timeline
3GPT-5.5 refuses to read full files
@badlogicgames
Mario Zechner, who ships the pi coding agent at pi.dev, reports that GPT-5.5 has been trained to refuse reading entire files and instead returns partial reads — degrading his agent in production. He compares the behavior directly to last week's Opus 4.7 regression complaints.
Read source“they thought gpt 5.5 to refuse reading full files. it sucks very very hard. this is opus all over again.”
pi coding agent moves to the earendil-works namespace
@badlogicgames
The pi GitHub repo moves to the earendil-works org and npm packages republish under @earendil-works as the project organizes under a company name. Old @mariozechner imports keep working at runtime, but type-checked extensions need to migrate, and extensions written against the new namespace will not work in older pi versions after today's release.
Read source“caveat: your extension will then no longer work in old pi versions after today's pi release. we need to rip this bandaid off. sorry.”
Anthropic's three priorities for the next Claude generation
Code with Claude keynote
At the Code with Claude opening keynote, Head of Product Research Dianne Penn named three areas: higher judgment and code taste for autonomous engineering, 'infinite' context combined with high-quality memory for long-running tasks, and multi-agent coordination. Each line maps onto an active research thread and tells you what the next Claude generation is trying to be good at.
Read source“Powering teams of agents and instances of Claude that collaborate on big goals that are far too big for any single instance ever could.”
Platform & policy
2Google folds reCAPTCHA into Cloud Fraud Defense, with a QR-code human-presence challenge
Google Cloud
reCAPTCHA is being rebranded and absorbed as the bot-detection layer of Google Cloud Fraud Defense, adopting Web Bot Auth and SPIFFE for agent identity. The new AI-resistant challenge is QR-code-based — verification gets pushed onto a separate human-held device because in-page CAPTCHAs are no longer reliable.
Read source“we enable application providers to deter and mitigate malicious requests by requesting humans to be in the loop using the new QR code-based challenge. This AI-resistant mitigation challenge to prove human presence is designed to make automated fraud economically unviable.”
EU pushes high-risk AI Act dates and bans nudification apps
European Commission
Political agreement on the Digital Omnibus simplification of the AI Act sets high-risk-system rules to apply from 2 December 2027 and product-integrated systems (lifts, toys) from 2 August 2028. The stated goal is to give technical standards and support tools time to land before enforcement begins; the same agreement bans nudification apps targeting non-consenting subjects.
Read source“Rules for systems used in certain high-risk areas — including biometrics, critical infrastructure, education, employment, migration, asylum and border control — will apply from 2 December 2027.”
Companion episode
The File That Wouldn't Read
Three of today's items rhyme: MOSAIC-Bench measures what production coding agents will do when they cannot see the whole picture, ProgramBench measures what they build when handed only a spec, and Workspace-Bench measures what they do when handed too much. The honest read across all three is that current agents are about half as good at structured, multi-file work as a competent human — and that the gap shows up most clearly when the surrounding harness, not the model, has to do the thinking.