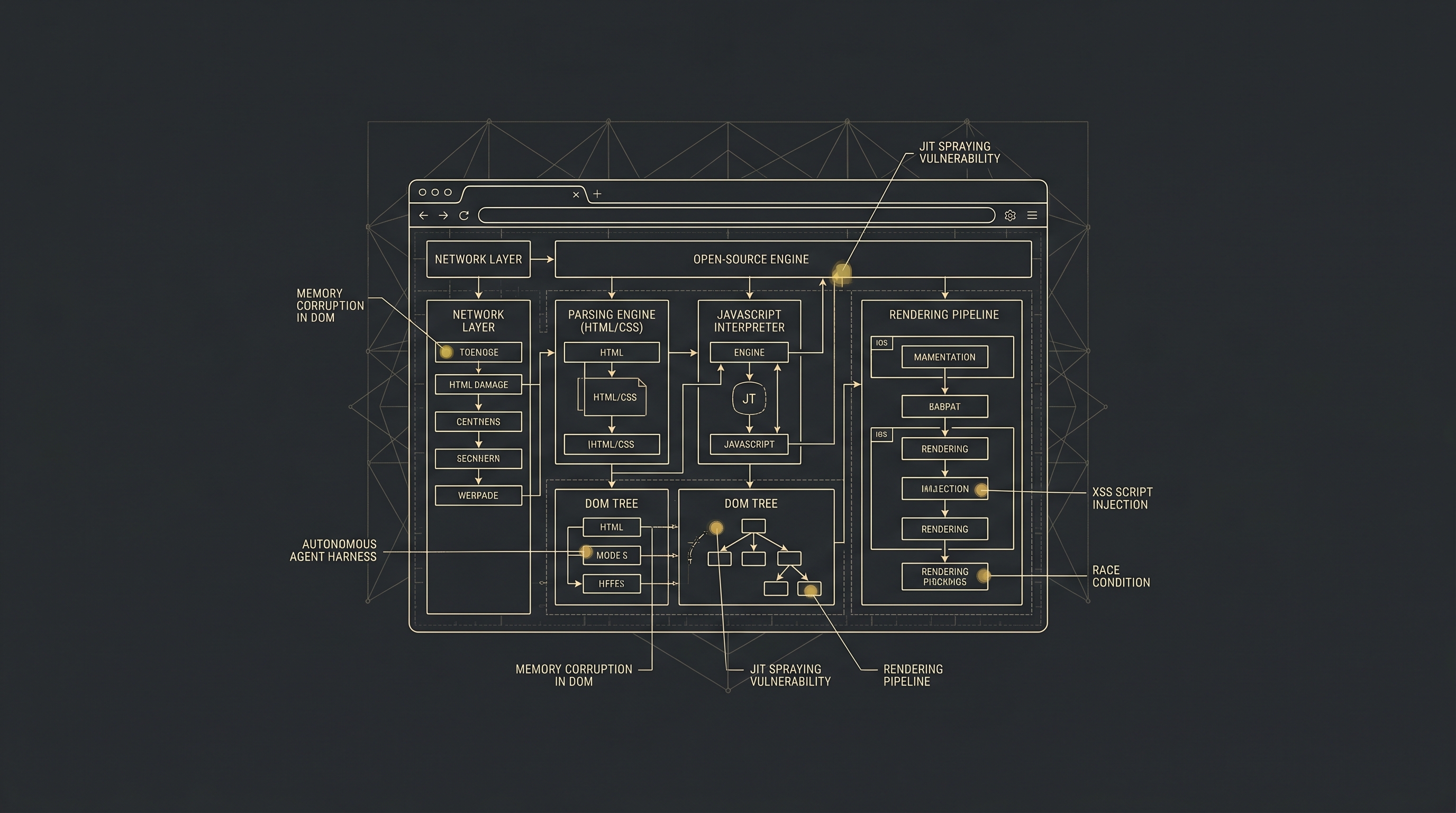
Mozilla wired an agentic harness around Claude Mythos Preview on top of its existing fuzzing infrastructure and shipped 271 bug fixes in Firefox 150. 180 were sec-high, many were sandbox escapes, and the haul included a 20-year-old XSLT bug and a 15-year-old <legend> bug — classes that fuzzing has historically struggled with. The team writes that any project can start today with simple prompting…
Read source◆ Braid Daily · 2026-05-08
Mozilla turns Claude on Firefox and ships 271 fixes
A frontier-lab harness wired around Claude Mythos Preview produced 271 Firefox 150 fixes, including a 20-year-old XSLT bug.
The lead
1
Models, agents, and what's inside them
4AlphaEvolve: a year of shipped deployments
Google DeepMind
DeepMind's coding agent has now landed across twelve concrete deployments: a circuit design integrated into next-generation TPU silicon, a 30% reduction in DeepConsensus genomics errors, an Optimal Power Flow solver moving from 14% to over 88% feasibility, and a 20% cut in Spanner LSM-tree write amplification. Klarna doubled training speed on a large transformer; FM Logistic saved over 15,000 km annually.
Read source“AlphaEvolve began optimizing the lowest levels of hardware powering our AI stacks. It proposed a circuit design so counterintuitive yet efficient that it was integrated directly into the silicon of our next-generation TPUs.”
Natural Language Autoencoders: translating Claude's thoughts
Anthropic
Anthropic trains a verbalizer and a reconstructor as two copies of Claude, scoring round-trip fidelity. NLAs surface evaluation-awareness on 26% of SWE-bench Verified problems versus less than 1% on real claude.ai usage, and they recovered a hidden motivation in an auditing-game test 12-15% of the time. Anthropic cautions that NLAs hallucinate and are best read for themes.
Read source“In a test of whether Claude takes destructive actions while writing code... NLA explanations show signs of evaluation awareness 16% of the time, even though Claude never explicitly verbalizes this.”
Three new audio models in the OpenAI API
OpenAI
GPT-Realtime-2 brings GPT-5-class reasoning to voice; GPT-Realtime-Translate covers 70+ input languages into 13 outputs; a third audio model rounds out the API surface.
Read sourceOpenAI is winding down the fine-tuning API
r/OpenAI
Existing customers can run training jobs through January 6, 2027; inference on already-fine-tuned models stays available until the underlying base model is deprecated. OpenAI's pitch is that base-model capability has caught up for most use cases — teams with fine-tuned 4o or 5 variants need a migration plan.
Read source“OpenAI is winding down the fine-tuning API and platform. Existing active customers can continue running fine-tuning training jobs through January 6, 2027, after which creating new training jobs will no longer be possible.”
Voice transport and on-prem inference
4OpenAI's WebRTC problem
moq.dev
An engineer who built the WebRTC SFUs at Twitch and Discord argues WebRTC is wrong for voice agents: it drops audio packets to keep conferencing latency low, takes a minimum of 8 round-trips to establish a connection where QUIC needs 1, and its ephemeral-port-per-connection model breaks at scale. His practical recommendation: stream over WebSockets today, move to QUIC/WebTransport when you need video or congestion-aware drops.
Read source“WebRTC is designed to degrade and drop my prompt during poor network conditions... I would much rather wait an extra 200ms for my slow/expensive prompt to be accurate.”
AMD Instinct MI350P: CDNA 4 on a PCIe card
ServeTheHome
AMD's first new Instinct PCIe card in nearly half a decade: 144 GB HBM3E, 4 TB/s memory bandwidth, 600W TBP, full-height full-length dual-slot, passively cooled. It's purpose-fab'd silicon, not a binning leftover. No Infinity Fabric exposed, so multi-card setups talk over PCIe Gen5 x16 only — an 8-card box runs 8 models well, but a single big model spread across cards is constrained.
Read sourceSkymizer announces HTX301
Skymizer
A Taiwanese accelerator startup pitches a single PCIe card with six chips, 384 GB total memory, ~240W power, and a claim of 700B-parameter inference on one card. The architecture pitch is to disaggregate prefill and decode with decode-first silicon. No public benchmarks, no third-party validation, no pricing — this is a marketing announcement, not a product to measure.
Read sourceMTP for llama.cpp: Gemma 4 26B at 138 tok/s
r/LocalLLaMA
Multi-Token Prediction drafters land in llama.cpp with quantized Gemma 4 assistants in GGUF. On an M5 Max MacBook Pro, Gemma 26B goes from 97 tok/s baseline to 138 tok/s with MTP — a 40% wallclock speedup on a real laptop.
Read sourceCompliance, supply chain, and consent
3EU AI Act Article 50 transparency draft opens for comment
European Commission
The draft Article 50 guidelines opened for stakeholder consultation today; feedback closes 3 June 2026. Rules become applicable 2 August 2026 — providers must inform users they're interacting with AI and implement machine-readable marks for synthetic content; deployers must disclose deep fakes, AI-generated public-interest publications, and emotion-recognition or biometric-categorization systems.
Read sourceMaybe you shouldn't install new software for a bit
Xe Iaso
Two new Linux kernel vulns landed alongside the earlier copy.fail family — 'Copy Fail 2: Electric Boogaloo' and 'Dirty Frag'. Iaso's recommendation: outside of distro kernel patches, hold off on installing new software for a week or so.
Read source“Right now would be one of the best times for a supply chain attack via NPM to hit hard.”
Open-OSS/privacy-filter is an infostealer on Hugging Face
r/LocalLLaMA
A Hugging Face 'model' named to typo-squat OpenAI's privacy filter packaged a Python loader that downloads a malicious PowerShell command, which spawns a PowerShell-launched EXE installed via Task Scheduler. Behavior analysis on tria.ge confirms infostealer behavior. The model registry is converging with the package registry.
Read sourceCompanion episode
Mozilla's 271 Bugs, Chrome's 4 Gigabytes, and a WebRTC Veteran Telling OpenAI to Stop
Two threads tying together this week: agentic harnesses are starting to ship real production work — Mozilla's 271 fixes today, the AlphaEvolve deployments — and the supply chain underneath all of it is getting more fragile, between the kernel pile, the Hugging Face infostealer, and Chrome's pre-consent install. Read both halves of the issue together.