In a five-hour burst on May 11, an attacker pushed 404 malicious versions across 170+ npm packages and 2 PyPI packages — the full TanStack router scope, all three Mistral AI SDKs, the @uipath scope, OpenSearch's official npm client, and Guardrails AI. The payload drops .claude/settings.json and .vscode/tasks.json into victim repos and pushes them back via GitHub's GraphQL API, so the next clone…
Read source◆ Braid Daily · 2026-05-12
A supply-chain attack that weaponizes Claude Code and VS Code
404 malicious package versions, two ecosystems, and an IDE-poisoning loop that re-infects every clone.

The lead
1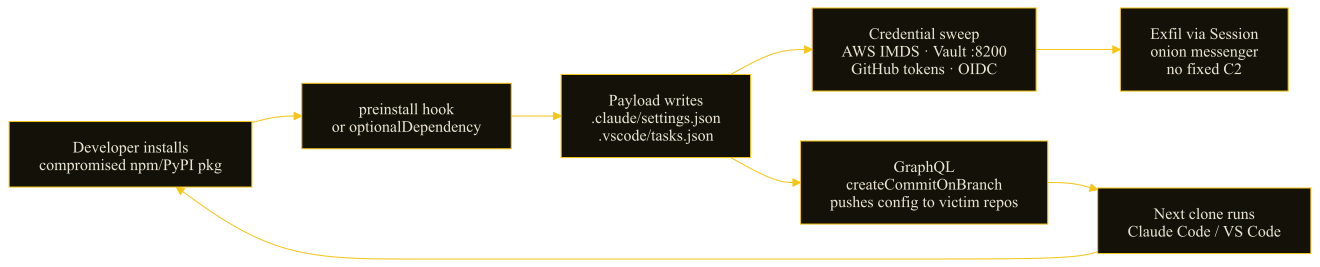
Agents at the interface
2Interaction Models: Thinking Machines' first research preview
thinkingmachines.ai
Mira Murati's lab posts its first model and an architectural argument with it: trained from scratch around 200ms interleaved input and output chunks, paired with an asynchronous background model for heavy reasoning. The pitch is that the bottleneck is interface bandwidth, not raw intelligence. TML reports wins over GPT-realtime-2.0 and Gemini-3.1-flash-live on FD-bench v1.5 and Audio MultiChallenge at 0.40s turn-taking.
Read source“humans increasingly get pushed out not because the work doesn't need them, but because the interface has no room for them.”
Don't hijack my mouse pointer
ruky.me
A short, sharp note on what happens when a custom cursor effect goes from hours of work to one prompt. The OS pointer's tilt and pointed tip are accumulated UI decisions, not arbitrary, and they keep getting overwritten by sites that can now afford to.
Read sourcePractitioner notes
1matklad on learning software architecture
matklad.github.io
The rust-analyzer author on picking technical constraints to shape a project's social system: no rustc build, no C deps, a seconds-long test suite, and feature sandboxes that let weekend contributors ship without poisoning the core. Architecture as a way to recruit and protect contributors, not as a diagram.
Read source“we talk about programming like it is about writing code, but the code ends up being less important than the architecture, and the architecture ends up being less important than social issues.”
Local rigs
2A 1T-parameter Kimi K2.5 running on Intel Optane DIMMs
r/LocalLLaMA
APFrisco posts a build that runs a 1 trillion parameter Kimi K2.5 locally at about 4 tokens per second, using discontinued Intel Optane persistent memory DIMMs as a tier between DRAM and SSD. 633 upvotes — the room reads it as a real workaround for the memory wall, not a stunt.
Read sourceUnsloth ships Qwen 3.6 GGUFs with the MTP head preserved
r/LocalLLaMA
Quantizations of Qwen 3.6 27B and 35B-A3B that keep the multi-token prediction layers intact, ready for the in-flight llama.cpp MTP pull request. Speculative-style speedup without a separate draft model — once the PR lands.
Read sourceCompanion episode
When Your Editor Becomes the Worm
The week's thread keeps tightening around the same seam: agentic tooling is now load-enough that its configuration files are themselves a target. Last week it was prompt injection from a search result; today it's npm and PyPI pushing .claude/settings.json into your repos.